Machine Learning Categories
Machine Learning (ML) use cases can be categorized into:
- Object Vision (detection, classification, segmentation, motion, etc. )
- Human Vision (face, pose, motion, etc.)
- Speech (translation, speech-to-text-to-speech, etc.)
- Voice (identification, etc.)
- Document analysis (categorize, sentiment, insight, etc.)
- Recommendation
- Forecasting or Projection
- Domain specific
Models Repository
Tensorflow - Models Zoo
Hosted at the Github- TensorFlow Models
is recommended START from here for learning. The repository is grouped by:
-
Official models are a collection of example models that use TensorFlow’s high-level APIs. They are intended to be well-maintained, tested, and kept up to date with the latest stable TensorFlow API. They should also be reasonably optimized for fast performance while still being easy to read. Recommend newer TensorFlow users to start here. [Further discussions]
-
Research models are a large collection of models implemented in TensorFlow by researchers. They are not officially supported or available in release branches; it is up to the individual researchers to maintain the models and/or provide support on issues and pull requests. [Further discussions]
-
Samples folder contains code snippets and smaller models that demonstrate features of TensorFlow, including code presented in various blog posts.
-
Tutorials folder is a collection of models described in the TensorFlow tutorials.
[Source: Github - Tensorflow Models readme]
Tensorflow - Official Models
Hosted in the official folder.
There are not that many models from the official collections, and most of them
are not commonly used in the online blogging. For example, the popular
object detection models are hosted at the “Research” model repo as
discussed here.
Current available models are:
- bert: A powerful pre-trained language representation model: BERT, which stands for Bidirectional Encoder Representations from Transformers.
- boosted_trees: A Gradient Boosted Trees model to classify higgs boson process from HIGGS Data Set.
- mnist: A basic model to classify digits from the MNIST dataset.
- resnet: A deep residual network that can be used to classify both CIFAR-10 and ImageNet’s dataset of 1000 classes.
- transformer: A transformer model to translate the WMT English to German dataset.
- wide_deep: A model that combines a wide model and deep network to classify census income data.
Tensorflow - Research Models
Hosted in the research folder.
There are at least 50 models in the
collections
including the popular
“object detection”
model found in the subfolder.
An in-depth discussion about how-to navigate the model repo is provided below for object detection; and for others in the future.
Object Detection
Hosted in the object_detection folder. The models are capable of localizing and identifying multiple objects in a single image, though it still remains a core challenge in computer vision. The TensorFlow Object Detection API is an open source framework built on top of TensorFlow that makes it easy to construct, train and deploy object detection models.
Follow the instructions below to navigate object detection repo:
-
checkout Table of Content
-
Go to g3doc documentation folder; the TOC also links to this folder
-
Must do, get familiar with the Installation
-
Tensorflow detection model zoo list all the different models, and provide links to download the models; this is where everyone download the models from.
Coral - Repo
URL: https://coral.withgoogle.com/models/
This repo hosts the pretrained so-called “Edge-TPU” models, .tflite file,
that is pre-compiled to run on the Edge TPU like Coral board.
To build your own model for the Edge TPU, you must use the provided
Edge TPU Compiler.
List of models include:
- Image classification: MobileNet v1 & v2 (trained on ImageNet), MobileNet v2 (trained on iNat: insect, plants, and birds), and Inception v1 to v4 (trained on ImageNet)
- Object detection: MobileNet SSD v1 (trained on COCO), and MobileNet SSD v1 (trained on Faces)
- Embedding extractor (classification) - MobileNet v1
AWSLab Model zoo
URL: https://github.com/awslabs/mxnet-model-server/blob/master/docs/model_zoo.md
Apache MXNet Model Zoo
URLs:
MXNet Model zoo has models in the following categories:
- CNN
- RNN
- GAN
- Other models
Gluon Model zoo has models in the following architectures:
- AlexNet
- DenseNet
- Inception V3
- ResNet V1
- ResNet V2
- SqueezeNet
- VGG
- MobileNet
- MobileNetV2
Also see the companion tutorial
OpenVINO Github
URL: https://github.com/opencv/open_model_zoo/blob/master/intel_models/index.md
- Object Detection Models
- Object Recognition Models
- Reidentification Models
- Semantic Segmentation Models
- Instance Segmentation Models
- Human Pose Estimation Models
- Image Processing
- Text Detection
- Text Recognition
- Action Recognition Models
- Compressed models
Tutorials
- MXNet
-
Gluon CV Toolkit MXNet models; extensive tutorial in: image classification, object detection, semantic segmentation, instance segmentation, pose estimation, GAN, and person re-id;
- TFLite
Benchmark - Inference Speed
The inference speed is governed by image size, model, hardware and framework but perhaps to a lesser extend.
Hardwares benchmark & Framework (Tensorflow vs TF-lite) benchmark
Alasdair Allan performed benchmarking for the following hardwares and published the results on the must-read article, Benchmarking Edge Computing, May 2019:
- Coral Dev Board (NXP i.MX 8M processor, Google Edge TPU, Setup, Specs)
- NVIDIA Jetson Nano (64-bit quad-core Arm Cortex-A57 CPU 1.43GHz, NVIDIA Maxwell GPU with 128 CUDA cores capable of 472 GFLOPs (FP16), 4GB of 64-bit LPDDR4 RAM onboard, 16GB of eMMC storage, Setup, Spec)
- Coral USB Accelerator with a Raspberry Pi ( Setup Specs)
- The original Movidus Neural Compute Stick with a Raspberry Pi ( Setup, Original article)
- Second generation Intel Neural Compute Stick 2 with a Raspberry Pi ( Setup)
- Apple MacBook Pro 2016 model [Quad-core 2.9 GHz Intel Core i7]
- Vanilla Raspberry Pi 3, Model B+ without any acceleration
The setup was to keep the model and framework the same as much as possible for each hardware. He compared two quite similar models pretrained by Google, both models use Tensorflow framework: Mobilenet v2 SSD trained with COCO dataset and Mobilenet v1 SSD 0.75 depth trained also with COCO dataset.
An single 3888×2916 pixel image was used which contained two recognizable objects, a banana and an apple. The image was resized down to 300×300 pixels before presenting it to the model, and each model was run 10,000 times before an average inferencing time was taken.
A companion article that compares Tensorflow and Tensorflow-Lite on Raspberry Pi was published later following the hardware benchmarking, Benchmarking TensorFlow and TensorFlow Lite on the Raspberry Pi. The combined results are presented here.
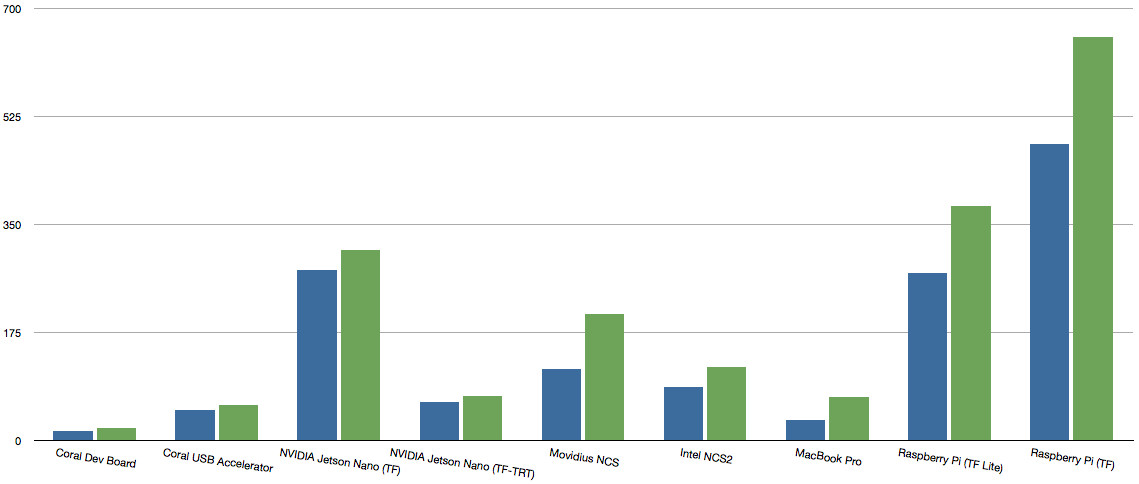
Source: Benchmarking TensorFlow and TensorFlow Lite on the Raspberry Pi
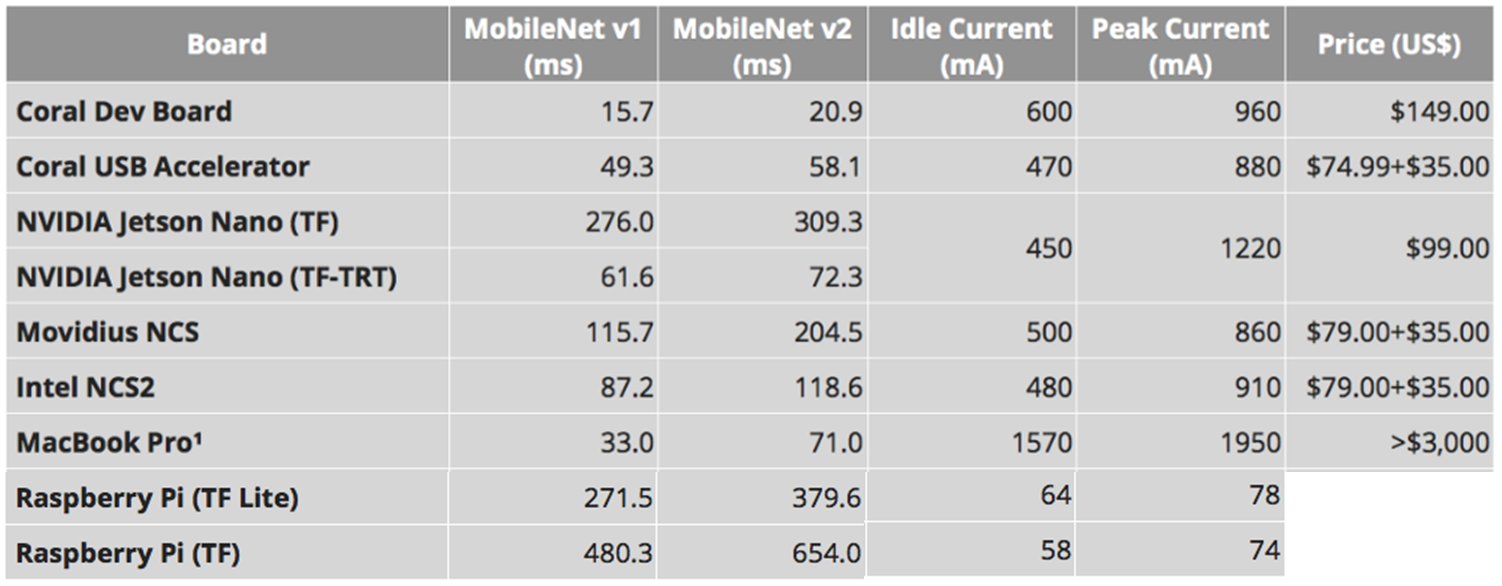
Sources: Benchmarking Edge Computing & Benchmarking TensorFlow and TensorFlow Lite on the Raspberry Pi
The inference time reported by Google is 31 ms and 26 ms, respectively, tested under the following conditions: 600x600 pixel image, time includes all pre and post-processing, and performed on desktop using an Nvidia GeForce GTX TITAN X card. They also advised that Mobilenet V2 is faster on mobile devices than Mobilenet V1, but is slightly slower on desktop GPU.
Frameworks
List of machine learning frameworks, high level descriptions and links to useful in-depth information.
Tensorflow
Start from Github Tensorflow repo and follow through to the end of the for links to good information.
Installation
Two very good sources, directly from Tensorfow, to start from:
-
Github Tensorflow repo - Installation install using
pipfor both CPU and GPU, other hardware architectures including Raspberry Pi, and nighly build -
Tensorflow website more detailed instructions; including; docker container, and Google Colab.
Dataset
ImageNet
URL: http://www.image-net.org/
Image database hosted by Stanford Vision Lab; the images are organized according to the Princenton University WordNet hierarchy (currently only the nouns), in which each node of the hierarchy is depicted by hundreds and thousands of images.
- Total images: 14,197,122 images, 21841 synsets indexed
- Categories: 1000
- Resolutions, pixels:
- Image types: natural
CIFAR10
URL: https://www.cs.toronto.edu/~kriz/cifar.html
- Total images: 60,000
- Categories: 10
- Resolutions, pixels: 32 x 32
- Image types: natural
COCO
URL: http://cocodataset.org/#explore
- Total images: 123,287 images, 886,284 instances
- Categories: 90
- Resolutions, pixels: tbd
- Image types: common objects; see below

Source: COCO dataset
PASCAL_VOC
URL: http://host.robots.ox.ac.uk/pascal/VOC/
Subset of ImageNet images with object bounding boxes.
- Total images: 1 million+
- Categories: 1000
- Resolutions, pixels:
- Image types: natural
UCF101
URL: http://crcv.ucf.edu/data/UCF101.php
Videos database.
- Total videos: 13,320
- Categories: 101 action categories
- Resolutions, pixels:
- Image types: action
Places2
URL: http://places2.csail.mit.edu/download.html
There are 1.6 million train images from 365 scene categories in the Places365-Standard, which are used to train the Places365 CNNs. There are 50 images per category in the validation set and 900 images per category in the testing set. Compared to the train set of Places365-Standard, the train set of Places365-Challenge has 6.2 million extra images, leading to totally 8 million train images for the Places365 challenge 2016. The validation set and testing set are the same as the Places365-Standard.
- Total images: 1.6 millions
- Categories: 365 scenes
- Resolutions, pixels:
- Image types: places
Mini-Places
URL: http://6.869.csail.mit.edu/fa15/project.html
Subset of the Places2 dataset.
- Total images: 100,000
- Categories: 100 scenes
- Resolutions, pixels:
- Image types: places
Multi-media commonly
URL: https://aws.amazon.com/public-datasets/multimedia-commons/
Images and videos from flickr. YFCC100M and supplementyal material (pre-extracted features, additional annotations).
- Total images: 99.2 millions
- Total videos: 0.8 million
- Categories: 100 scenes
- Resolutions, pixels:
- Image types: natural
Visipedia on Github
URL: https://github.com/visipedia
Kitti dataset
URL: http://www.cvlibs.net/datasets/kitti/index.php
A project of Karlsruhe Institute of Technology and Toyota Technological Institute at Chicago. Images & videos: stereo, optical flow, visual odometry, 3D object detection and 3D tracking; taken from a standard station wagon with two high-resolution color and grayscale video cameras. Accurate ground truth is provided by a Velodyne laser scanner and a GPS localization system. The datasets are captured by driving around the mid-size city of Karlsruhe, in rural areas and on highways. Up to 15 cars and 30 pedestrians are visible per image. Besides providing all data in raw format, benchmarks were extracted for each task; and for each of our benchmarks, also provide an evaluation metric and this evaluation website.
- Total images: tbd
- Total videos: tbd
- Categories: tbd
- Resolutions, pixels: tbd
- Image types: tbd
Open Image dataset
URL: https://storage.googleapis.com/openimages/web/index.html
- Total images: tbd
- Total videos: tbd
- Categories: tbd
- Resolutions, pixels: tbd
-
Image types: tbd
-
15,851,536 boxes on 600 categories
-
2,785,498 instance segmentations on 350 categories
-
36,464,560 image-level labels on 19,959 categories
-
391,073 relationship annotations of 329 relationships
- Extension - 478,000 crowdsourced images with 6,000+ categories
AVA dataset
URL: https://research.google.com/ava/
Audiovisual annotations of video for improving our understanding of human activity. The annotated videos are all 15 minute long movie clips. Each of the clips has been exhaustively labeled by human annotators, and the use of movie clips in the dataset is expected to enable a richer variety of recording conditions and representations of human activity.
- Total images: tbd
- Total videos: tbd
- Categories: tbd
- Resolutions, pixels: tbd
- Image types: tbd

Source: AVA dataset
iNaturalist dataset
URL: https://github.com/visipedia/inat_comp/blob/master/2017/README.md#bounding-boxes
For the training set, the distribution of images per category follows the observation frequency of that category by the iNaturalist community. Therefore, there is a non-uniform distribution of images per category.
- Total images: 579,184 training images and 95,986 validation images
- Total videos: tbd
- Categories: 5,089
- Resolutions, pixels: tbd
- Image types: tbd
CIFAR-10 dataset
URL: http://www.cs.toronto.edu/~kriz/cifar.html
- Total images: 60000
- Total videos: none
- Categories: 10
- Resolutions, pixels: 32x32 colour images
- Image types: airplane, automobile, bird, cat, deer, dog, frog, horse, ship, truck
CALTECH-101
URL:
- http://www.vision.caltech.edu/Image_Datasets/Caltech101/
- http://www.robots.ox.ac.uk:5000/~vgg/research/caltech/index.html
Pictures of objects belonging to 101 categories. About 40 to 800 images per category. Most categories have about 50 images.
- Total images: 60000
- Total videos: none
- Categories: 101; 40 to 800 images per category. Most categories have about 50 images.
- Resolutions, pixels: 300 x 200 colour images
- Image types: various

Source: Caltech dataset
CALTECH-256
URL: http://www.vision.caltech.edu/Image_Datasets/Caltech256/
- Total images: 30607
- Total videos: none
- Categories: 256;
- Resolutions, pixels: ? colour images
- Image types: various
Training
Image sources
Check the license thoroughly before using:
-
Pixabay some images are free;
Image Annotation Tools
-
labelImg written in Python and uses Qt for its graphical interface; the annotations are saved as XML files in the PASCAL VOC format. May have problems opening
jpgon MAC OSX, if so convert topng; -
FIAT Fast Image Annotation Tool; handle image data annotation, data augmentation, data extraction, and result visualisation/validation. Requires OPENCV 3 and Google Protobuf.
Image format conversion Tools
- ImageMagick create, edit, compose, or convert bitmap images. It can read and write images in a variety of formats (over 200) including PNG, JPEG, GIF, HEIC, TIFF, DPX, EXR, WebP, Postscript, PDF, and SVG. Use ImageMagick to resize, flip, mirror, rotate, distort, shear and transform images, adjust image colors, apply various special effects, or draw text, lines, polygons, ellipses and Bézier curves.